Identificare le fasi prodromiche della demenza attraverso l’analisi computazionale del linguaggio: quindici anni di ricerche sull’italiano *
Gloria Gagliardi, Fabio Tamburini
Dipartimento di Filologia Classica e Italianistica
Alma Mater Studiorum – Università di Bologna
Contributo presentato da Rema Rossini Favretti †
Abstract
Early identification of cognitive impairment, especially in the subclinical phases of neurodegenerative diseases, is a key challenge for modern healthcare. Traditional screening tools often fail to detect the subtle language and cognitive changes that precede dementia. Given the strong evidence that language is one of the earliest faculties affected by neurodegeneration, linguistic analysis is emerging as a promising tool for early diagnosis. This paper presents a novel approach developed by the University of Bologna’s Department of Classical Philology and Italian Studies, which uses Natural Language Processing (NLP) and Artificial Intelligence (AI) to automatically analyze patients’ speech. By extracting linguistic biomarkers from semi-spontaneous vocal recordings, the method aims to support early detection of cognitive decline and offers a preliminary communicative profile of Italian-speaking individuals with dementia.
Keywords
Natural Language Processing, Dementia Diagnosis, Digital Linguistic Biomarkers.
© Gloria Gagliardi, Fabio Tamburini 2025 / Doi: 10.30682/annalesps2503g
This is an open access article distributed under the terms of the CC BY 4.0 license
* Questo lavoro offre una sintesi dei lavori condotti e pubblicati dal nostro gruppo di ricerca nell’ultimo quindicennio, qui ricompresi in una riflessione più ampia sul possibile ruolo delle scienze del linguaggio e del Natural Language Processing in ambito clinico. Le ricerche presentate sono state finanziate dai progetti OPLON – Opportunities for active and healthy LONgevity (MUR, Smart Cities and Communities, SCN_00176), ReMIND – An ecological, cost-effective AI platform for early detection of prodromal stages of cognitive impairment (European Union – NextGenerationEU, PRIN 2022, 2022YKJ8FP – CUP J53D23008380006) e AKiD – Acoustic and Kinematic Characteristics of Speech in Dementia (European Union – NextGenerationEU, PRIN 2022 PNRR, P2022MMH7R – CUP J53D23017290001).
La nostra gratitudine va dunque ai colleghi che con noi hanno condiviso questo percorso, non soltanto per il lavoro condotto insieme “sul campo”, ma anche per i preziosi momenti di confronto e i numerosi spunti di riflessione. In mero ordine alfabetico ringraziamo dunque Giorgia Albertin, Daniela Beltrami, Paolo Bongioanni, Laura Calzà, Sabina Capellari, Cristina Dolciotti, Marcello Ferro, Enrico Ghidoni, Alessandro Lento, Elena Martinelli, Claudia Marzi, Chiara Meluzzi, Andrea Nadalini, Yuka Naito, Vito Pirrelli, Rema Rossini Favretti, Maria Ranù, Alice Todesco e Shibingfeng Zhang.
Dedichiamo questo lavoro alla memoria di Rema Rossini Favretti che tanto ha creduto negli anni in questa metodologia di analisi e tanto ha fatto per la nostra formazione durante la nostra carriera accademica. L’articolo è stato ideato e redatto congiuntamente dai due autori. Ai soli fini accademici, Gloria Gagliardi è responsabile dei §§ 1, 2 e 3, mentre Fabio Tamburini ha curato i §§ 4, 5 e 6.
1. Introduzione
L’individuazione del deterioramento cognitivo – in particolare se indotto da malattie da misfolding proteico – nelle sue fasi sub- e pre-cliniche rappresenta una sfida cruciale per i sistemi sanitari. Una diagnosi tempestiva dei Disturbi Neurocognitivi [1] consente infatti di proporre precocemente trattamenti terapeutici, riabilitativi e assistenziali, di pianificare in maniera personalizzata gli interventi, e conseguentemente di migliorare la qualità di vita dei pazienti riducendo al contempo il carico psicologico che grava sui caregiver e l’impatto economico sulla spesa pubblica [2].
Nonostante l’ampia disponibilità di test per la valutazione dello stato cognitivo, le metodologie di screening attualmente in uso (test “carta e matita”) si rivelano poco sensibili nel rilevare le sottili compromissioni cognitive che caratterizzano le fasi prodromiche della demenza, e soprattutto di predirne la progressione [3]. Sempre più evidente è dunque la necessità di esplorare nuovi domini di analisi in grado di affiancare i tradizionali strumenti neuropsicologici [4].
Numerose evidenze scientifiche dimostrano che il linguaggio, in quanto facoltà cognitiva complessa, risulta pervasivamente e prodromicamente interessato dai processi neurodegenerativi [5]: grazie ai progressi raggiunti nel settore del Trattamento Automatico del Linguaggio naturale (NLP – Natural Language Processing) e dell’Intelligenza Artificiale (AI) si stanno perciò aprendo nuove opportunità per l’individuazione di biomarker [6], [7].
Dagli anni Dieci del Duemila il nostro gruppo di ricerca, attivo presso il dipartimento di Filologia Classica e Italianistica dell’Università di Bologna, ha ideato un nuovo metodo che sfrutta tecniche di NLP e AI per individuare i primi segnali di declino cognitivo attraverso l’analisi automatica di registrazioni vocali [8], [9], [10]. L’articolo illustrerà le fondamenta teoriche di tale approccio e descriverà la metodologia di estrazione dei biomarker linguistici dal parlato semispontaneo dei pazienti, presentando al contempo alcuni casi di studio.
In particolare, nel §2 verranno cursoriamente inquadrati eziopatogenesi, epidemiologia (§2.1) e correlati linguistici dei Disturbi Neurocognitivi (§ 2.2); nel §3 verrà definito il concetto di “Biomarker Linguistico Digitale” (DLB, Digital Linguistic Biomarker), ovvero verrà illustrata la possibilità di eseguire screening su larga scala e a basso costo mediante l’estrazione automatica di indicatori quantitativi dall’eloquio dei pazienti; il §4 sarà dedicato alla presentazione della pipeline computazionale per l’estrazione dei DLBs sviluppata dal nostro gruppo di ricerca; alla rassegna di casi di studio di successo è riservato il § 5. Infine, nel § 6, verranno tratte le conclusioni e delineate possibili linee di ricerca future.
2. Background
2.1. Eziopatogenesi ed epidemiologia dei Disturbi Neurocognitivi
Il termine Disturbo Neurocognitivo Maggiore, comunemente noto come “demenza”, si riferisce a una sindrome clinica di eziologia eterogenea, generalmente a decorso progressivo, caratterizzata da un declino delle capacità cognitive rispetto ad un precedente livello di funzionamento dell’individuo, superiore a quanto ci si possa attendere dal normale processo di invecchiamento e tale da interferire con l’autonomia nelle attività della vita quotidiana. Nei pazienti che ne sono affetti, i sintomi cognitivi (ad esempio deficit di memoria, linguaggio e orientamento visuospaziale) si associano di solito ad alterazioni comportamentali, psicologiche e neurovegetative [11]. Si tratta dunque di una condizione gravemente invalidante, determinata da una disfunzione neurologica acquisita. Sotto il profilo eziopatogenetico è possibile distinguere tra forme primarie, derivanti da processi neurodegenerativi responsabili di una progressiva e irreversibile perdita neuronale (disordini da misfolding proteico come la malattia di Alzheimer, strettamente connessi all’invecchiamento), e forme secondarie, che insorgono in conseguenza di patologie potenzialmente trattabili e reversibili che inducono declino cognitivo. Tra queste ultime si annoverano disfunzioni endocrine e metaboliche, malattie infiammatorie del sistema nervoso centrale, stati da carenza nutrizionale, neoplasie e traumi encefalici [12].
La demenza ha un impatto elevatissimo in termini sia epidemiologici, sia di ricadute sul tessuto sociale: secondo le stime dell’Alzheimer’s Disease International, nel 2019 oltre 50 milioni di persone nel mondo erano affette da questa condizione, numero destinato a triplicare entro il 2050 come effetto dell’aumento dell’aspettativa di vita della popolazione [13]. Tali proiezioni dovranno certamente essere riconsiderate nei prossimi anni alla luce dell’impatto che la pandemia da SARS-CoV-2 ha avuto sulla popolazione anziana; sebbene ad oggi non sia ancora disponibile un quadro sistematico sugli effetti del Covid-19 in relazione alle condizioni specifiche che contribuiscono alla vulnerabilità geriatrica nei soggetti con deterioramento cognitivo [14], né sia possibile stimarne con esattezza l’impatto sulla prevalenza delle malattie età-correlate [15], il fenomeno delle demenze non cessa di essere “un rilevante problema di salute pubblica” [16].
In tale contesto, la gestione di un numero sempre crescente di individui fragili rappresenta una sfida cruciale per i sistemi sanitari globali.
I trattamenti farmacologici attualmente disponibili per le demenze primarie sono di natura sintomatica: in altri termini, non sono in grado di agire direttamente sui meccanismi patogenetici alla base dell’accumulo proteico cerebrale responsabile della malattia, e dunque di influenzare il decorso a lungo termine del processo neurodegenerativo, ma si limitano ad attenuarne le manifestazioni cliniche. Tale processo, tuttavia, inizia molti anni prima della comparsa di sintomi clinici evidenti: questa fase preclinica, definita MCI – Mild Cognitive Impairment [17] o Disturbo Neurocognitivo Lieve [1], rappresenta una zona “grigia” tra l’invecchiamento fisiologico ed una fragilità cognitiva di rilievo patologico, ed offre una finestra strategica per sviluppare trattamenti farmacologici e approcci terapeutici innovativi e mirati [18]. Il miglioramento della tempestività e dell’accuratezza diagnostica rappresenta perciò oggi uno degli obiettivi chiave delle strategie sanitarie internazionali.
La diagnosi di demenza è di competenza neurologica: si basa sull’identificazione di deficit cognitivi oggettivabili mediante test neuropsicologici mirati (e.g., memoria, linguaggio, funzioni visuospaziali, comportamento), affiancata da neuroimaging strutturale (TAC o RMN, per evidenziare possibili atrofie cerebrali o lesioni vascolari) e funzionale (PET, al fine di rilevare ipometabolismo in specifiche aree encefaliche) e possibilmente dell’analisi liquorale tramite puntura lombare per il dosaggio dei biomarcatori specifici.
Negli ultimi anni sono stati sviluppati numerosi strumenti psicometrici di valutazione dei deficit cognitivi: tuttavia quelli più comunemente utilizzati nei presidi sanitari – Mini Mental State Examination (MMSE, [19]) e Montreal Cognitive Assessment (MoCA, [20]) in particolare – presentano limiti significativi nella rilevazione dei primi segni di declino cognitivo [3]. Indubbiamente risultano indispensabili (e rappresentano lo strumento clinico d’elezione) per identificare casi di demenza clinicamente manifesti, ma ancora mostrano, ad oggi, scarsa sensibilità nell’individuare i primissimi segni della fragilità cognitiva [21]. L’esigenza di disporre di test più accurati, sensibili e applicabili su larga scala a costi contenuti è perciò sempre più urgente.
2.2. Il linguaggio nelle demenze dovute a malattie da misfolding proteico
Numerose evidenze suggeriscono la presenza di deficit linguistici in diverse patologie neurodegenerative [5], [22]. Questo riscontro è particolarmente evidente nelle demenze primarie, di cui le alterazioni del linguaggio – a livello sia formale, sia funzionale – rappresentano un sintomo onnipresente, persino nelle fasi iniziali.
Ne è un chiaro esempio la malattia di Alzheimer (AD – Alzheimer’s Dementia), condizione a cui in letteratura è stato dedicato il maggior spazio, in ragione dell’alta prevalenza epidemiologica. Sebbene il declino della memoria episodica e delle abilità visuospaziali costituisca il nucleo sintomatologico prevalente di tale tipo di demenza, un deterioramento progressivo del linguaggio è costantemente presente [23], [24], [25], [26], [27]. Diversamente dalle afasie classiche di natura vascolare o traumatica, causate da lesioni cerebrali focali, i disturbi del linguaggio osservati nell’AD si inseriscono in un quadro di compromissione cognitiva globale, che coinvolge anche le funzioni esecutive, il ragionamento e le abilità visuocostruttive. I pazienti presentano frequentemente una riduzione della conoscenza semantica e lessicale, difficoltà nel recupero delle parole (i.e., anomia, parafasie semantiche), compromissione della comprensione sia orale che scritta, calo della fluenza verbale e una ridotta densità informativa [28], [29]. Tali sintomi emergono precocemente e tendono a intensificarsi, riflettendo un deterioramento progressivo della memoria semantica, ovvero quella componente della memoria a lungo termine che custodisce conoscenze concettuali, lessicali e culturali [30]. Dal punto di vista fonetico, il linguaggio dei pazienti con AD è caratterizzato, a livello macroscopico, da una diminuzione della velocità di eloquio e da un aumento di esitazioni e disfluenze [31], [32], [33]. L’elaborazione sintattica appare relativamente preservata all’onset, sebbene siano stati osservati enunciati strutturalmente meno complessi, contenenti errori morfosintattici con maggior frequenza rispetto ai soggetti di controllo [32], [34], [35]. Infine, a livello discorsivo, i pazienti tendono a produrre testi più brevi, poveri di contenuti rilevanti e caratterizzati da numerosi errori; gli enunciati sono spesso vaghi ed incoerenti, sono stati evidenziati problemi di coesione referenziale, una pianificazione povera e difficoltà di astrazione [34], [36], [37], [38], [39]. Le capacità di ripetizione e articolazione, invece, risultano per lo più preservate. Tuttavia, con l’avanzare della malattia, i sintomi linguistici si aggravano fino a compromettere completamente la comprensione del discorso e a ridurre la produzione verbale a ecolalia e stereotipie.
La presenza di un disturbo linguistico “isolato” (ovvero con risparmio relativo delle altre principali funzioni cognitive, memoria episodica e abilità visuospaziali in primis) è l’elemento essenziale per la diagnosi clinica di Afasia Progressiva Primaria (PPA – Primary Progressive Aphasia); la sindrome si caratterizza per un esordio caratterizzato da un subdolo e progressivo deterioramento della produzione verbale, evidente sia nella produzione spontanea, sia attraverso una valutazione standardizzata [40]. Sono attualmente riconosciute tre varianti di PPA su base clinica-anatomica [41], [42]: i) una variante non fluente/agrammatica (nfvPPA), tipicamente associata ad atrofia perisilviana anteriore sinistra, che si caratterizza per scarsa fluenza, disprosodia, presenza di errori articolatori, agrammatismo e deficit nella comprensione di frasi sintatticamente complesse; ii) una variante semantica (svPPA), stabilmente associata ad atrofia focale (anche in questo caso prevalentemente sinistra) dei lobi temporali anteriori, mesiali e inferiori, che si manifesta con perdita del vocabolario e compromissione della conoscenza delle parole, inquadrabili in un disturbo più ampio della memoria semantica; iii) una variante logopenica (lvPPA), neuroanatomicamente correlata ad un danno della giunzione temporo-parietale sinistra (sebbene l’estensione e la simmetria dell’atrofia di questa regione varino sensibilmente tra i pazienti), che si distingue per difficoltà nel recupero lessicale e compromissione della memoria di lavoro fonologica, evidente da difficoltà nella ripetizione di frasi.
Al contrario, compromissioni linguistiche non sono tipicamente associate alla demenza a corpi di Lewy (LBD – Dementia with Lewy bodies) e alla Demenza da Parkinson (PDD – Parkinson’s disease dementia, [43]), se non per quanto riguarda gli aspetti esclusivamente fonetici (in particolar modo articolatori) e prosodici dell’eloquio. Tuttavia, ad un’analisi più specifica, sono stati osservati deficit nei compiti di denominazione e nella fluenza verbale [44], oltre a disturbi di natura pragmatica (i.e., organizzazione narrativa, coerenza tematica) [45].
Attenzione crescente stanno ricevendo i disturbi linguistici nelle fasi precliniche della compromissione cognitiva. Nei soggetti con Mild Cognitive Impairment (MCI) si osservano alterazioni simili a quelle della demenza lieve o moderata [46], [47]. I disturbi più frequentemente riportati includono una ridotta fluenza verbale [48] e difficoltà nella denominazione [49], ma è nell’ambito pragmatico che si registrano i maggiori deficit. È stato ampiamente documentato che cambiamenti nel discorso (povertà semantica, incoerenza, difficoltà referenziali, perseverazioni narrative) possono essere tra i segni più precoci della malattia, riscontrabili molti anni prima dell’emergere di altri sintomi cognitivi evidenti [39], e possano rappresentare un importante predittore della progressione dall’MCI in demenza. Questa ultima osservazione è largamente sostenuta da studi longitudinali retrospettivi, che hanno dimostrato come anche in anziani cognitivamente normali in apparenza, sottili alterazioni linguistiche anticipassero l’insorgenza di un deterioramento cognitivo successivamente rivelatosi clinicamente rilevante [23], [50], [51].
3. Marker prodromici della neurodegenerazione: sul ruolo predittivo delle alterazioni linguistiche
Come già anticipato nel § 2.1, gli strumenti psicodiagnostici tradizionali, in particolar modo quelli “carta e matita”, mostrano una bassa sensibilità nell’individuazione di cambiamenti sottili nella cognizione. In aggiunta, pur essendo la loro somministrazione lunga e costosa (i.e., almeno due ore sono necessarie per una valutazione completa durante una visita di approfondimento di secondo livello, neurologica o geriatrica), non consentono di esplorare molti aspetti del linguaggio, a livello segmentale (es. articolatorio) e soprattutto soprasegmentale (i.e., prosodico). La combinazione di bassa ecologicità ed alto costo li rende quindi difficilmente applicabili con finalità di screening su larga scala.
Al contrario, crescono le evidenze a sostegno della fattibilità dell’analisi automatica dell’eloquio come strumento efficace per affrontare questa sfida. Per quanto esposto nel §2.2, il linguaggio è infatti un dominio cognitivo soggetto ad erosione fin dalle primissime fasi del processo neuropatologico che conduce alla demenza: essendo il suo processamento radicato in reti neurali ampiamente distribuite [52], anche lievi alterazioni a livello corticale o sottocorticale possono indurre la comparsa di sottili cambiamenti nella qualità della produzione verbali. Tali modifiche sono, il più delle volte, così sfumate da non poter essere rilevate attraverso l’osservazione qualitativa diretta, nemmeno se condotta da un linguista esperto; possono tuttavia essere quantificate in modo molto preciso a partire da testi scritti, registrazioni audio grezze o trascrizioni grazie all’utilizzo di metodi NLP, fungendo così da indicatori per finalità di screening o diagnosi di condizioni cliniche [6], [53]. In altri termini, all’interno di tale paradigma metodologico, anche minime perturbazioni del linguaggio possono agire come “biomarcatori digitali” (DLBs – Digital Linguistic Biomarkers): “objective, quantifiable behavioral data that can be collected and measured by means of digital devices, allowing for a low-cost pathology detection, classification and monitoring” [7].
Si noti che il processo di estrazione dei DLB è completamente non invasivo, rapido ed economico: quest’analisi non richiede infatti infrastrutture o attrezzature mediche complesse né laboratori specializzati ed è in linea di principio è addirittura effettuabile a distanza grazie alle tecnologie di telemedicina già in uso [54].
Da una prospettiva teorica, inoltre, riteniamo non sia irrilevante sottolineare quanto negli ultimi anni il concetto di riproducibilità dei risultati della ricerca si sia affermato come principio chiave di rigore metodologico, non soltanto nel campo delle scienze “dure”, ma anche per la ricerca sociale e comportamentale [55]. Gran parte del lavoro condotto nell’alveo delle scienze del linguaggio, dalla creazione di risorse linguistiche all’analisi dei dati, si basa tradizionalmente su giudizi soggettivi [56]. Sebbene i metodi utilizzati nella ricerca linguistica siano ampiamente accettati e considerati generalmente non controversi nonostante questa limitazione “intrinseca” [57], tale componente soggettiva rappresenta de facto una delle principali barriere all’integrazione tra le scienze umane e scienze della salute, dominio in cui l’oggettività è considerata un requisito epistemologico fondamentale [58]. Certamente permangono ancora numerose criticità che la comunità scientifica è chiamata ad affrontare nei prossimi anni, ma un numero crescente di evidenze empiriche suggerisce che l’utilizzo dei DLBs possa consentire di superare l’impasse, e determinare un cambiamento significativo nella pratica clinica: questo approccio intrinsecamente interdisciplinare rappresenta una soluzione promettente alle sfide cliniche che abbiamo illustrato grazie alla capacità di coniugare oggettività e riproducibilità dell’analisi con l’effettiva sostenibilità dei costi a carico dei sistemi sanitari [53].
4. Una pipeline computazionale per l’estrazione dei Biomarker
Linguistici Digitali
La necessità di individuare un metodo efficiente per correlare caratteristiche linguistiche e disturbi mentali con finalità di screening, specificamente utilizzabile con parlanti di lingua italiana, ci ha portato a mettere a punto una pipeline computazionale in grado di estrarre un ampio insieme di DLB dalle produzioni orali o scritte applicando tecniche di NLP [10].
In particolare, la pipeline è strutturata come un insieme complesso di moduli di elaborazione flessibili che interagiscono tra loro. La Fig. 1 ne illustra la struttura.
Questo strumento può elaborare tre diversi tipi di input: registrazioni vocali (come file audio non compresso, WAV), testi scritti grezzi (TXT) o testi pre-elaborati contenenti analisi morfosintattiche e sintattiche (memorizzate nel formato standardizzato CoNLL1). La Tab. 1 elenca l’insieme completo dei DLB prodotti dalla pipeline suddivisi in sei gruppi di biomarcatori:
– Feature derivate dalla lingua parlata: DLB acustici (SPE) o ritmici (RHY).
– Feature derivate dal testo, cioè DLB lessicali (LEX), sintattici (SYN), basati sul dizionario psicologico Linguistic Inquiry and Word Count (LWC) e di leggibilità (REA).

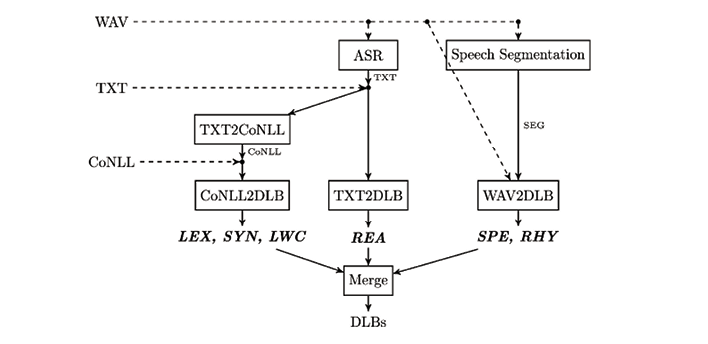
Fig. 1. Struttura della pipeline descritta nel § 4. È possibile fornire l’input a vari livelli ma, nel caso più generale, solo la registrazione della produzione orale del soggetto (WAV) sarà disponibile e tutti i moduli della pipeline dovranno estrarre le feature partendo da questo dato.
Per motivi di spazio, non è possibile illustrare nel dettaglio ciascuno di questi indici. Per una descrizione più precisa e i dettagli sul calcolo il lettore può fare riferimento a Calzà et al. [9].
Dato un tipo di input specifico – ovvero un file WAV, TXT o CoNLL – la pipeline calcola “a cascata” tutti i DLB che possono essere derivati da esso. Il set più ampio si ottiene fornendo la registrazione vocale (da sola o accompagnata dalla trascrizione manuale, per evitare eventuali errori prodotti dal modulo di Automatic Speech Recognition descritto poco più avanti): per ampiezza e ricchezza di indici estraibili, nonché per applicabilità a contesti clinici reali, è indubbiamente questo il setting sperimentale ideale nell’ottica di creare uno strumento idoneo allo screening di massa.
Tab. 1. Lista dei DLB estratti automaticamente dalla pipeline. Per maggiori dettagli si rinvia a Calzà et. al. [9].
|
|
|
|
– Durata dei segmenti di silenzio – Durata dei segmenti contenenti emissioni vocali – Regolarità temporale dei segmenti sonori – Verbal rate – Transformed phonation rate – Standardized phonation time – Standardized pause rate – Root mean square energy – Pitch – Spectral centroid – Higuchi fractal dimension |
– Content density – Incidenza delle Part-of-Speech – Reference rate to reality – Incidenza dei deittici personali, spaziali e temporali – Incidenza di pronomi relativi avverbi di negazione – Ricchezza lessicale: TTR, Brunet’s & Honore ́’s Indexes – Incidenza dei verbi di azione – Frequency-of-use tagging – Propositional idea density – Numero medio di parole negli enunciati |
|
|
|
|
– Percentuali degli intervalli vocalici – Durata degli intervalli vocalici and consonantici – Pairwise variability index – Variation coefficient |
– Metriche linguistiche (e.g., parole per frase) – Parole funzione (e.g., pronomi, articoli, ecc.) – Parole legate all’espressione delle emozioni (e.g., positive/negative) – Processi cognitivi (e.g., insight, certezza, ecc.) – Processi percettivi (e.g., vista, udito, tatto) – Processi biologici (e.g., corpo, salute/malattia, ecc.) – Argomenti personali (e.g., lavoro, svago, denaro, ecc.) – Parole sociali (e.g., famiglia, amici) – Punteggiatura |
|
|
|
|
– Complessità del sintagma nominale (i.e., numero di elementi dipendenti dalla testa nominale) – Global dependency distance – Complessità Sintattica – Syntactic embeddedness: massima profondità dell’albero sintattico – Lunghezza dell’enunciato |
|
|
|
|
|
– Indici READ-IT per valutazione della leggibilità (a livello lessicale, morfosintattico, sintattico e globale) |
Per calcolare i DLB i dati di input devono essere pre-elaborati applicando strumenti di analisi vocale di base e tecniche di NLP:
– Conversione da voce a testo. Se l’input consiste solo in una registrazione, la trascrizione del parlato rappresenta un requisito fondamentale per l’estrazione di DLB affidabili relativi al testo. In questo senso, il riconoscimento automatico del parlato, task noto anche come
speech-to-text o Automatic Speech Recognition (ASR), riveste un ruolo fondamentale. A questo scopo, abbiamo inserito nella pipeline uno specifico modulo ASR basato sulle più recenti innovazioni nel settore dei Large Language Model (LLM) basati su Transformer [59].
– Segmentazione del parlato. Per estrarre direttamente gli indici fonetici dall’eloquio, i campioni devono essere segmentati. A tal fine, la pipeline utilizza un rilevatore di attività vocale (VAD – Voice Activity Detector) specificamente progettato per l’analisi di interviste che identifica le regioni che contengono parlato rispetto a quelle occupate da silenzi o rumore. Queste segmentazioni forniscono informazioni cruciali per il calcolo di alcune caratteristiche acustiche, come la durata dei segmenti di silenzio, la durata dei segmenti vocali e i loro rapporti. È inoltre necessario ricavare la trascrizione fonetica allineata temporalmente per calcolare la durata di vocali, consonanti e il rapporto dei loro intervalli. L’approccio perseguito nella versione attuale della pipeline prevede la conversione grafema-fonema della trascrizione ortografica e il successivo allineamento temporale della trascrizione fonetica e del segnale acustico.
– Analisi del testo trascritto. Questa fase richiede solitamente alcuni passaggi di pre-elaborazione per ricavare alcune caratteristiche linguistiche di base. Il nostro algoritmo sfrutta il pacchetto software Stanford STANZA, una raccolta di strumenti basati su reti neurali profonde per l’analisi linguistica di numerose lingue, organizzati in una pipeline coerente per l’elaborazione del testo [60]. In particolare, questo strumento esegue i task di tokenizzazione, lemmatizzazione, etichettatura delle parti del discorso (Part of Speech Tagging) e analisi sintattica a livello di frase (modulo TXT2CoNLL in Fig. 1).
Alcuni degli indici elencati nella Tabella 1 sono strettamente correlati all’articolazione del parlato e quindi relativi all’elaborazione fonetica (modulo WAV2DLB). Altri coinvolgono caratteristiche legate al testo e possono essere invece calcolati sia su produzioni scritte che sulle trascrizioni delle sessioni di parlato (moduli CoNLL2DLB e TXT2DLB).
5. Casi di studio di successo
Negli ultimi 15 anni abbiamo applicato con successo versioni progressivamente più avanzate della pipeline per studiare i profili comunicativi di vari disturbi mentali.
Il dominio prevalente di interesse è stato ovviamente l’individuazione dei correlati linguistici del deterioramento cognitivo lieve e della demenza a fini diagnostici. In particolare, in un articolo del 2018 con prima firma Beltrami viene descritto il primo tentativo di estrazione e valutazione statistica del potere discriminativo di biomarker linguistici digitali dall’eloquio semi-spontaneo di pazienti con disturbo neurocognitivo lieve/moderato e controlli sani bilanciati per età, sesso ed educazione. Lo studio, condotto grazie al finanziamento ricevuto per il progetto OPLON, ha individuato diverse micro-alterazioni dell’eloquio a livello acustico, lessicale e sintattico in grado di distinguere le due coorti, e quindi potenziali indicatori di stadi preclinici di declino cognitivo [8]. In seguito, in Calzà et al. [9] e Gagliardi & Tamburini [10, sono stati testati diversi algoritmi di apprendimento automatico (es. Support Vector Machine, Random Forrest e Decision Tree) per classificare automaticamente i parlanti come soggetti sani e MCI, raggiungendo punteggi di F1 elevati, intorno al 75%: una prestazione allo stato dell’arte per questo specifico compito.
La stessa metodologia è stata successivamente applicata a testi scritti prodotti da adolescenti con diagnosi clinica di Anoressia Nervosa e coetanee normopeso [61], ipotizzando che le peculiari caratteristiche psicologiche del disturbo (in particolare il disturbo nella percezione dell’immagine corporea, il pensiero rigido dicotomico e i tratti ansiosi o depressivi associati al profilo cognitivo delle pazienti) determinino pattern linguistici particolari. Anche in questo caso, si è dimostrato un ambito cruciale il livello sintattico, in particolare lunghezza della frase, struttura del sintagma nominale e complessità sintattica globale. Abbiamo attribuito questo peculiare modello di erosione linguistica al severo (ma reversibile) deterioramento di natura metabolica che colpisce il sistema nervoso centrale nell’Anoressia Nervosa e più in generale ad una debole coerenza centrale legata a deficit di natura esecutiva.
Infine, abbiamo utilizzato questi stessi marcatori per profilare le capacità comunicative dei bambini in età prescolare, misurando il potere discriminativo degli indizi acustici e ritmici a supporto della classificazione di bambini con Disturbo Primario del Linguaggio (DPL) vs. bambini con sviluppo linguistico e cognitivo normotipico, [62]. A tal fine, abbiamo trascritto manualmente registrazioni vocali raccolte da una coorte bilanciata di sedici bambini con esposizione linguistica monolingue (8 bambini con Disturbo di Linguaggio con deficit confinati al dominio espressivo e 8 coetanei con acquisizione tipica) per evitare la degradazione dei risultati dovuta agli errori introdotti dal modulo ASR tipicamente legati alle peculiari caratteristiche frequenziali ed articolatorie alla voce in età evolutiva. L’analisi ha dimostrato che, persino dopo la riabilitazione terapeutica, alcune caratteristiche spettrali della voce sono in grado di distinguere i bambini con deficit linguistico dai coetanei. A nostro avviso questi risultati, seppur preliminari, sono estremamente rilevanti poiché alcuni degli indici che con maggiore accuratezza distinguono i due gruppi non sono udibili all’orecchio umano, anche se esperto, esulando dalle possibilità dei test neuropsicologici convenzionali.
Ad oggi, l’effettiva relazione tra gli specifici marker linguistici individuati e i sintomi clinici di queste patologie non è completamente chiara: per far luce su questo punto è necessario raccogliere prove più ampie.
6. Conclusioni
I risultati dei nostri studi, e molti altri in letteratura, suggeriscono che le batterie standard di test neuropsicologici tradizionali possano essere efficacemente combinate con analisi di biomarker linguistici ricavati dalle produzioni linguistiche parlate di pazienti con strumenti computazionali. Mentre i test neuropsicologici e le valutazioni strutturate hanno un impatto rilevante sulla naturalezza delle risposte del soggetto, l’analisi delle produzioni linguistiche parlate naturali può offrire un test ecologico, non invasivo, economico e affidabile per lo screening dei pazienti a rischio, anche da parte dei medici di medicina generale. Inoltre, la rilevanza statistica di numerosi biomarker linguistici (acustici, lessicali e sintattici) suggerisce che un’analisi multidimensionale completa delle competenze comunicative sia preferibile a un’analisi che coinvolga singoli domini.
È possibile prevedere in un prossimo futuro l’estensione in ottica multilingue di questa tecnologia: il sistema che abbiamo sviluppato, specificamente ideato per essere utilizzato su parlanti italofoni, è stato infatti di recente adattato con successo alla lingua inglese; in occasione della Challenge PROCESS Prediction and Recognition Of Cognitive declinE through Spontaneous Speech, che si è tenuta nell’ambito della Conferenza Internazionale IEEE ICASSP 2025 – International Conference on Acoustics, Speech, and Signal Processing, l’algoritmo si è classificato primo nel task di classificazione [63].
Concludendo, nonostante il nostro gruppo lavori già da parecchi anni in questa direzione e i risultati siano molto incoraggianti, sono certamente necessarie ulteriori indagini per convalidare le ipotesi di partenza e fornire alla comunità medica un dispositivo che sia realmente in grado di fornire un’indicazione rispetto a outcome clinicamente significativi: l’espressione dei sintomi è infatti mediata da una miriade di fattori demografici, sociali e cognitivi, che la rende altamente eterogenea al momento della rilevazione. Gli aspetti più critici riguardano senza dubbio l’esigua quantità di dati che i singoli progetti riescono a raccogliere sul campo e l’impossibilità, dovuta alle attuali regolamentazioni in termini di dati personali sensibili, di condividere registrazioni tra gruppi di ricerca differenti, magari in una prospettiva internazionale.
Bibliografia
1. American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders: Fifth Edition Text Revision DSM-5-TR™; American Psychiatric Association Publishing: Washington (DC), 2022.
2. Rasmussen, J.; Langerman, H. Alzheimer’s Disease – Why We Need Early Diagnosis. Degenerative neurological and neuromuscular disease, 2019, 9, 123-130. doi: 10.2147/DNND.S228939.
3. Alzola, P.; Carnero, C.; Bermejo-Pareja, F.; Sánchez-Benavides, G.; Peña-Casanova, J.; Puertas-Martín, V.; Fernández-Calvo, B.; Contador, I. Neuropsychological Assessment for Early Detection and Diagnosis of Dementia: Current Knowledge and New Insights. Journal of Clinical Medicine, 2024, 13(12), 3442. doi: 10.3390/jcm13123442.
4. Calzà, L.; Beltrami, D.; Gagliardi, G.; Ghidoni, E.; Marcello, N.; Rossini-Favretti, R; Tamburini, F. Should we screen for cognitive decline and dementia? Maturitas, 2015, 82(1), 28-35. doi: 10.1016/j.maturitas.2015.05.013.
5. Boschi, V.; Catricalà, E.; Consonni, M.; Chesi, C.; Moro, A.; Cappa, S.F. Connected speech in neurodegenerative language disorders: A review. Frontiers in Psychology, 2017, 8, 269. doi: 10.3389/fpsyg.2017.00269.
6. Gagliardi, G. Natural language processing techniques for studying language in pathological ageing: A scoping review. International Journal of Language & Communication Disorders, 2024, 59(1), 110-122. doi: 10.1111/1460-6984.12870.
7. Gagliardi, G.; Kokkinakis, D.; Duñabeitia, J. Editorial. Digital linguistic biomarkers: Beyond paper and pencil tests. Frontiers in Psychology, 2021,12, 752238. doi: 10.3389/fpsyg.2021.752238.
8. Beltrami, D.; Gagliardi, G.; Rossini Favretti, R.; Ghidoni, E.; Tamburini, F.; Calzà, L.
Speech analysis by natural language processing techniques: A possible tool for very early detection of cognitive decline? Frontiers in Aging Neuroscience, 2018,10, 369. doi: 10.3389/fnagi.2018.00369.
9. Calzà, L.; Gagliardi, G.; Rossini Favretti, R.; Tamburini, F. Linguistic features and automatic classifiers for identifying Mild Cognitive Impairment and dementia. Computer Speech & Language, 2021, 65, 101-113. doi: 10.1016/j.csl.2020.101113.
10. Gagliardi, G.; Tamburini, F. (2021). Linguistic biomarkers for the detection of Mild Cognitive Impairment. Lingue e Linguaggio, 2021, XX.1: 3-31. doi: 10.1418/101111.
11. Cerejeira, J.; Lagarto, L.; Mukaetova-Ladinska, E. Behavioral and psychological symptoms of dementia. Frontiers in Neurology, 2012, 73(3), 719125. doi: 10.3389/fneur.2012.00073.
12. Papagno, C.; Bolognini, N. Neuropsicologia delle demenze. Il Mulino: Bologna, 2020.
13. Patterson, C. The World Alzheimer Report 2018. Technical report, Alzheimer’s Disease International, 2018.
14. Bianchetti, A.; Bellelli, G.; Guerini, F.; Marengoni, A.; Padovani, A.; Rozzini, R.; Trabucchi, M. Improving the care of older patients during the Covid-19 pandemic. Aging Clinical and Experimental Research, 2020, 32(9), 1883-1888. doi: 10.1007/s40520-020-01641-w.
15. Andrasfay, T.; Goldman, N. Reductions in US life expectancy during the COVID-19 pandemic by race and ethnicity: Is 2021 a repetition of 2020? PLoS ONE, 2022, 17(8), e0272973. doi: 10.1371/journal.pone.0272973.
16. WHO and Alzheimer’s Disease International. Dementia: a public health priority. Geneva: World Health Organization: Geneva, 2012.
17. Petersen, R.C. Clinical practice. Mild Cognitive Impairment. New England Journal of Medicine, 2011, 364(23), 2227-2234. doi: 10.1056/NEJMcp0910237.
18. Ritchie, K.; Ropacki, M.; Albala, B.; Harrison, J.; Kaye, J.; Kramer, J.; Randolph, C.; Ritchie, C.W. Recommended cognitive outcomes in preclinical Alzheimer’s disease: Consensus statement from the European Prevention of Alzheimer’s Dementia project. Alzheimer’s & Dementia, 2017, 13, 186-195. doi: 10.1016/j.jalz.2016.07.154.
19. Folstein, M.; Folstein, S.E.; McHugh, P.R. “Mini-Mental State”: a practical method for grading the cognitive state of patients for the clinician. Journal of Psychiatric Research, 1975, 12, 189.198. doi: 10.1016/0022-3956(75)90026-6.
20. Nasreddine, Z.S.; Phillips, N.A.; Bédirian,V.; Charbonneau, S.; Whitehead, V.; Collin, I.; Cummings, J.L.; Chertkow, H. The Montreal Cognitive Assessment, MoCA: A brief screen-
ing tool for Mild Cognitive Impairment. Journal of the American Geriatrics Society, 2005, 53(4), 695-699. Doi: 10.1111/j.1532-5415.2005.53221.x.
21. Mortamais, M.; Ash, J.A.; Harrison, J.; Kaye, J.; Kramer, J.; Randolph, C.; Pose, C.; Albala, B.; Ropacki, M.; Ritchie C.W.; Ritchie K. Detecting cognitive changes in preclinical Alzheimer’s disease: A review of its feasibility. Alzheimer’s & Dementia, 2017, 13, 468-492. doi: 10.1016/j.jalz.2016.06.2365.
22.Gumus, M.; Koo, M.; Studzinski, C.M.; Bhan, A.; Robin, J.; Black S.E. (2024). Linguistic changes in neurodegenerative diseases relate to clinical symptoms. Frontiers in Neurology, 2024 15, 1373341. doi: 10.3389/fneur.2024.1373341.
23. Ahmed, S.; Haigh, A.M.F.; De Jager, C.A.; Garrard P. Connected speech as a marker of dis-
ease progression in autopsy-proven Alzheimer’s disease. Brain, 2013, 136 (12), 3727-3737. doi: 10.1093/brain/awt269.
24. Forbes-McKay, K.; Shanks, M.F.; Venneri A. Profiling spontaneous speech decline in Alzheimer’s disease: a longitudinal study. Acta Neuropsychiatrica, 2013, 25(6), 320-327. doi:10.1017/neu.2013.16.
25. Olmos-Villaseñor, R.; Sepulveda-Silva, C.; Julio-Ramos, T.; Fuentes-Lopez, E.; Toloza-Ramirez, D.; Santibañez, R.A.; Copland, D.A.; Mendez-Orellana, C. Phonological and Semantic Fluency in Alzheimer’s Disease: A Systematic Review and Meta-Analysis. Journal of Alzheimer’s disease, 2023, 95(1), 1-12. doi: 10.3233/JAD-221272.
26. Szatloczki, G.; Hoffmann, I.; Vincze, V.; Kalman, J.; Pakaski, M. Speaking in Alzheimer’s disease, is that an early sign? Importance of changes in language abilities in Alzheimer’s dis-
ease. Frontiers in Aging Neuroscience, 2015, 7, 195. doi: 10.3389/fnagi.2015.00195.
27. Williams, E.; McAuliffe, M.; Theys, C. Language changes in Alzheimer’s disease: A systematic review of verb processing. Brain and Language, 2021, 223, 105041. doi: 10.1016/j.bandl.2021.105041.
28. Catricalà, E.; Della Rosa, P.; Plebani, V.; Perani, D.; Garrard, P.; Cappa, S.F. Semantic feature degradation and naming performance. Evidence from neurodegenerative disorders. Brain & Language, 2015,147, 5865. doi: 10.1016/j.bandl.2015.05.007.
29. Fraser, K.C.; Meltzer, J.A.; Rudzicz, F. Linguistic features identify Alzheimer’s Disease in narrative speech. Journal of Alzheimer’s Disease, 2016, 49, 407-422. doi: 10.3233/JAD-150520.
30. Tulving, E. (1972). Episodic and Semantic Memory. In E. Tulving & W. Donaldson (eds.), Organization of Memory; Academic Press: New York, 1972, pp. 381-403.
31. Kavé, G.; Goral, M. Word retrieval in connected speech in Alzheimer’s disease: a review with meta-analyses. Aphasiology, 2017, 32(1), 4-26. doi: 10.1080/02687038.2017.1338663.
32. Sajjadi, S.A.; Patterson, K.; Tomek, M.; Nestor, P.J. Abnormalities of connected speech in semantic dementia vs. Alzheimer’s disease. Aphasiology, 2012, 26(6), 847-866. Doi: 10.1080/02687038.2012.654933.
33. Young, C.B.; Smith, V.; Karjadi, C.; Grogan, S.M.; Ang, T.F.A.; Insel, P.S.; Henderson, V.W.; Sumner, M.; Poston, K.L.; Au, R.; Mormino, E.C. Speech patterns during memory recall relates to early tau burden across adulthood. Alzheimers Dement, 2024, 20(4), 2552-2563. doi: 10.1002/alz.13731.
34. Chapin, K.; Clarke, N.; Garrard, P.; Hinzen, W. A finer-grained linguistic profile of Alzheimer’s disease and Mild Cognitive Impairment. Journal of Neurolinguistics, 2022, 6, 101069. doi: 10.1016/j.jneuroling.2022.101069.
35. Kemper, S.; LaBarge, E.; Ferraro, H.; Richard Cheung, F.; Cheung, H.; Storandt, M. On the preservation of syntax in Alzheimer’s Disease. Archives of neurology, 1993, 50(1), 81-86. doi: 10.1001/archneur.1993.00540010075021.
36. Albertin, G.; Martinelli, E. Exploring the Use of Cohesive Devices in Dementia within an Elderly Italian Semi-spontaneous Speech Corpus. In Dell’Orletta, F.; Lenci, A.; Montemagni, S.; Sprugnoli, R. (Eds.), Proceedings of the Tenth Italian Conference on Computational Linguitics (CLiC-it 2024), CEUR Workshop Proceedings 3878; CEUR-WS Team: Aachen, 2024, pp. 13-19. https://aclanthology.org/2024.clicit-1.3/.
37. Chapman, S.B.; Zientz, J.; Weiner, M.F.; Rosenberg, R.N.; Frawley, W.H.; Burns, M.H. Discourse changes in early Alzheimer disease, Mild Cognitive Impairment, and normal aging. Alzheimer Disease & Associated Disorders, 2002, 16(3), 177-186. doi: 10.1097/00002093-200207000-00008
38. de Lira, J.O.; Cianciarullo Minett, T.S.; Ferreira Bertolucci, P.H.; Ortiz, K.Z. Evaluation of macrolinguistic aspects of the oral discourse in patients with Alzheimer’s disease. International Psychogeriatrics, 2019, 31(9), 1343-1353. doi: 10.1017/S1041610218001758.
39. Drummond, C.; Coutinho, G.; Fonseca, R.P.; Assunção, N.; Teldeschi, A.; de Oliveira-Souza, R.; Moll, J.; Tovar-Moll, F.; Mattos; P. Deficits in narrative discourse elicited by visual stimuli are already present in patients with Mild Cognitive Impairment. Frontiers in Aging Neuroscience, 2015, 7, 96. doi: 10.3389/fnagi.2015.00096.
40. Mesulam, M. Primary Progressive Aphasia: A language-based dementia. New England Journal of Medicine, 2003, 349(16), 1535-1542. doi: 10.1056/NEJMra022435.
41. Belder, C.R.S.; Marshall, C.R.; Jiang, J.; Mazzeo, S.; Chokesuwattanaskul, A.; Rohrer, J.D.; Volkmer, A.; Hardy, C.J.D.; Warren, J.D. Primary progressive aphasia: six questions in search of an answer. Journal of Neurology, 2024, 271(2), 1028-1046. doi: 10.1007/s00415-023-12030-4.
42. Gorno-Tempini, M.L.; Hillis, A.; Weintraub, S.; Kertesz, A.; Mendez, M.; Cappa, S.F.; Ogar, J.; Rohrer, J.D.; Black, S.E.; Boeve, B.; Manes, F.; Dronkers, N.; Vandenberghe, R.; Rascovsky, K.; Patterson, K.; Miller, B.L.; Knopman, D.S.; Hodges, J.R.; Mesulam, M.; Grossman M. Classification of Primary Progressive Aphasia and its variants. Neurology, 2011, 76, 1006-1014. doi: 10.1212/WNL.0b013e31821103e6.
43. Prasad, S.; Katta, M.R.; Abhishek, S.; Sridhar, R.; Valisekka, S.S.; Hameed, M.; Kaur, J.; Walia, N. Recent advances in Lewy body dementia: A comprehensive review.
Disease-a-month, 2023, 69(5), 101441. doi: 10.1016/j.disamonth.2022.101441.
44. Bourgeais, A.; Trogneux, L.; Bella, S.B.; Comon, M.; Renard, A.; Balageas, A.C. Troubles du langage dans la maladie à corps de Lewy: une revue de la littérature. Gériatrie et psychologie neuropsychiatrie du vieillissement, 2024, 22(3), 365-371. doi: 10.1684/pnv.2024.1185.
45. Ash, S.; McMillan, C.; Gross, R.G.; Cook, P.; Morgan, B.; Boller, A.; Dreyfuss, M.; Siderowf, A.; Grossman, M. The organization of narrative discourse in Lewy body spectrum disorder. Brain & Language, 2011, 119, 30-41. doi: 10.1016/j.bandl.2011.05.006.
46. Mueller, K.D.; Hermann, B.; Mecollari, J.; Turkstra, LS. Connected speech and lan-
guage in mild cognitive impairment and Alzheimer’s disease: A review of picture description tasks. Journal of clinical and experimental neuropsychology, 2018, 40(9), 917-939. doi: 10.1080/13803395.2018.1446513.
47. Taler, V.; Phillips, N.A. Language performance in Alzheimer’s disease and Mild Cognitive Impairment: A comparative review. Journal of Clinical and Experimental Neuropsychology, 2008, 30(5), 501-556. doi: 10.1080/13803390701550128.
48. Tsantali, E.; Economidis, D.; Tsolaki, M. Could language deficits really differentiate Mild Cognitive Impairment (MCI) from mild Alzheimer’s disease? Archives of gerontology and geriatrics, 2013, 57(3), 263-270. doi: 10.1016/j.archger.2013.03.011.
49. Ahmed, S.; Arnold, R.; Thompson, S.A.; Graham, K.S.; Hodges, J.R. Naming of objects, faces and buildings in Mild Cognitive Impairment. Cortex, 2008, 44(6), 746-752. doi: 10.1016/j.cortex.2007.02.002.
50. Berisha, V.; Wang, S.; LaCross, A.; Liss, J. Tracking discourse complexity preceding Alzheimer’s disease diagnosis: a case study comparing the press conferences of Presidents Ronald Reagan and George Herbert Walker Bush. Journal of Alzheimer’s disease, 2015, 45(3), 959-963. doi: 10.3233/JAD-142763.
51. Oulhaj, A.; Wilcock, G.K.; Smith, A.D.; de Jager, C.A. Predicting the time of conversion to MCI in the elderly: role of verbal expression and learning. Neurology, 2009, 73(18), 1436-1442. doi: 10.1212/WNL.0b013e3181c0665f.
52. Fedorenko, E.; Ivanova, A.; Regev, T. The language network as a natural kind within the broader landscape of the human brain. Nature Reviews Neuroscience, 2024, 25, 289-312. doi: 10.1038/s41583-024-00802-4.
53. Gagliardi, G. The bodily substrate of language: insights from clinical linguistics. Lingue e Linguaggio, 2025, XXIV.1: 41-59.
54. König, A.; Satt, A.; Sorin, A.; Hoory, R.; Derreumaux, A.; David, R.; Robert, P.H. Use of speech analyses within a mobile application for the assessment of cognitive impairment in elderly people. Current Alzheimer Research, 2018, 2(15), 120-129. doi: 10.2174/1567205014666170829111942
55. Berez-Kroeker, A.L.; Gawne, L.; Kung, S.S.; Kelly, B.F.; Heston, T.; Holton, G.; Pulsifer, P.; Beaver, D.I.; Chelliah, S.; Dubinsky, S.; Meier, R.P.; Thieberger, N.; Rice, K.; Woodbury, A.C. Reproducible research in linguistics: A position statement on data citation and attribution in our field. Linguistics, 2018, 56(1), 1-18. doi: 10.1515/ling-2017-0032.
56. Artstein, R.; Poesio, M. Inter-coder agreement for computational linguistics. Computational Linguistics, 2008, 34(4), 555-596. doi: 10.1162/coli.07-034-R2.
57. Aroyo, L.; Welt, C. Truth is a lie: Crowd truth and the seven myths of human annotation. AI Magazine, 2015, 36(1), 15-24. doi: 10.1609/aimag.v36i1.2564.
58. Boudreau, J.D.; Cassell, E.J; Fuks, A. The clinical method and subjectivity in medicine. In Physicianship and the Rebirth of Medical Education; Oxford University Press: Oxford, 2018, pp. 99-110. doi: 10.1093/oso/9780199370818.003.0007.
59. Tamburini, F. (2022). Neural Models for the Automatic Processing of Italian; Patron: Bologna, 2022.
60. Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. (2020). Stanza: A Python natural language processing toolkit for many human languages. In A. Celikyilmaz, A.; Wen, T.H. (Eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations; ACL: Stroudsburg (PA) 2020; pp. 101-108. doi: 10.18653/v1/2020.acl-demos.14.
61. Cuteri, V.; Minori, G.; Gagliardi, G.; Tamburini, F.; Malaspina, E.; Gualandi, P.; Rossi, F.; Moscano, M.; Francia, V.; Parmeggiani, A. Linguistic feature of anorexia nervosa: a prospective case-control pilot study. Eating and weight disorders, 2022, 27(4), 1367-1375. doi: 10.1007/s40519-021-01273-7.
62. Gagliardi, G.; Tamburini, F.; Innocenti, M. Can speech-based measures support developmental language disorder identification? An explorative study. Studi Italiani di Linguistica Teorica e Applicata, 2023, LII (2), 383-401.
63. Zhang, S.; Khlif, N.; Ferro, M.; Gagliardi, G.; Tamburini, F. Cognitive decline detection using DLB extraction pipelines. In IEEE International Conference on Acoustics, Speech and Signal Processing, 2005, 1-2. Piscataway (New Jersey): IEEE. https://doi.org/10.1109/ICASSP49660.2025.10890866.